| _models | ||
| config | ||
| illustrations | ||
| .gitignore | ||
| export_script.sh | ||
| fanzine_generate.sh | ||
| find_characters_in_book.py | ||
| follow_progress.py | ||
| gantt_parser.py | ||
| generate_BD.sh | ||
| generate_book.sh | ||
| generate_illustration.sh | ||
| git_save.sh | ||
| graphique_gantt_intrigues.png | ||
| install_dependances_ubuntu.sh | ||
| intrigues.org | ||
| LICENSE | ||
| livre.org | ||
| make_ebook.sh | ||
| make_intrigues_to_csv.py | ||
| README.md | ||
| render_ebook.py | ||
| stats_chapitres.py | ||
| structure_generator.py | ||
| style.css | ||
| table_des_matieres.sh | ||
| up_infos.sh | ||
| update_book.sh | ||
| variables.sh | ||
{kind=link}
Générateur de livre au format orgmode ou makdown
Ce générateur permet de créer des dossiers dédiés à la rédaction de livres et vise une utilisation avec votre éditeur favori de simples fichiers textes au format orgmode ou markdown.
Vos écrits, vos données dans un format simple et libre.
Il vous permet de structurer votre récit en plusieurs documents, et de récolter des informations sur votre rédaction avec quelques scripts python.
Les fichiers orgmode générés disposent d'un identifiant unique généré aléatoirement afin d'être utilisable avec org-roam et d'autres gestionnaires de wiki personnel.
Prérequis:
- bash
- python
- pandoc
- matplotlib (pour les diagrammes de gantt)
- argparse
sudo apt install python pandoc python-pip pip install matplotlib argparse
Démarrer
Après avoir installé les dépendances, vous pouvez générer un dossier de nouveau livre. Attention, la génération d'un dossier supprime celui qui existait précédemment. Celui ci contiendra différents fichiers orgmode ou markdown avec une copie des scripts présents ici afin de pouvoir rendre le travail sur le livre transportable.
bash generate_book.sh le_nom_du_livre
Et hop, vous obtenez un sous dossier le_nom_du_livre qui contient de quoi faire avancer votre histoire.
J'ai rédigé un article de blog pour donner des conseils sur la rédaction d'une histoire à partir de ce que j'ai appris durant mes études d'art : https://tykayn.fr/2024/ecrire-une-histoire-et-ses-personnages-toute-une-aventure
À quoi servent les différents fichiers
Livre
C'est ici que votre récit se déroule. Tous les chapitres sont censés s'y trouver. Vous pouvez mettre des commentaires au sein du texte avec des marqueurs Orgmode de cmomentaires.
Afin d'avoir une structure qui aura visuellement du sens pour l'autrice du livre, seuls les titres ayant un tag :title: seront rendus lors de l'export. Cela permet de sectionner les étapes de l'histoire sans afficher ces titres de sections dans le livre final. Votre livre peut contenir des médias, nous vous invitons à les placer dans le dossier "assets". Le dossier "inspirations" est destiné à avoir des images, des médias, des documents divers, une bibliographie, c'est toujours utile de référencer ses inspirations pour clarifier ce que l'on aimerait raconter.
Personnages
Donnez des alias à vos personnages dans la ligne prévue à cet effet afin de comptabiliser leurs mentions dans le script find_characters_in_book.py
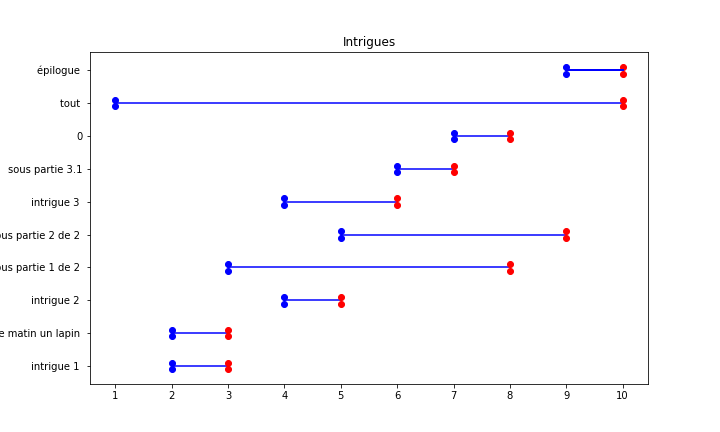
Intrigues
Les intrigues sont des arcs narratifs qui peuvent se superposer dans votre histoire.
Pour avoir cette vision des superpositions, le script make_intrigues_to_csv.py liste les entêtes et recherche si elles contiennent deux nombres séparés par un tiret.
Par exemple :
** l'intrigue bidule chose 4-9
Indique que l'on souhaite que cette intrigue débute dans la partie 4 et se termine dans la partie 9. Sans information de numérotation, on part du principe qu'une intrigue dure 1 partie de l'histoire, dans l'ordre des intrigues. Pour rester simples, ce générateur ne propose pas de drag and drop pour modifier ces informations. Les contributions au code pour simplifier cela sont bienvenues ;)
Notes d'intention
Décrit les thématiques que vous souhaitez aborder et ce que vous souhaitez exprimer, c'est un pense bête pour ne pas oublier une vue très macroscopique de ce que vous souhaitez faire avec votre livre.
Les scripts
Permettent de transformer votre livre en produit distribuable: ebook, html, pdf, mais aussi d'avoir une meilleure vue sur votre livre avec un tableau listant automatiquement les occurences de vos personnages trouvés dans chaque chapitre ainsi qu'un diagramme montrant les superpositions d'intrigues. Voir pour cela les descriptions dans À quoi servent les différents fichiers
Génération de plan de livre
python structure_generator.py
Génère un plan de chapitres selon les nombres de chapitres, de sous parties, et d'objectif de mots par section donnés.
Il ne reste plus qu'à copier le texte donné dans livre.org ou a utliser la sortie du script pour écrire dans un fichier.
Conversion du livre
Conversion en epub, html, et pdf grâce à pandoc.
python render_ebook.py
Statistiques
bash up_infos.sh
Mettre à jour mon livre
Ce dépot évolue, pour profiter de ses évolutions il vous suffit de copier les scripts dans le dossier de votre livre.
bash update_book.sh nom_du_dossier_livre
Tâches personnelles
On utilise par défaut des fichiers Orgmode, alors n'oublions pas de jeter un oeil à ce que l'on pourrait faire avec ce fichier taches_nom_de_mon_livre.org. à commencer par l'ajouter à sa liste de fichiers dans son agenda personnel.
Développement en cours
Objectifs de rédaction en nombre de mots plus fins.
Par défaut, le script déterminant la tenue des objectifs de rédaction se base sur une valeur fixe pour tous les chapitres.
Vous pouvez modifier cet objectif dans stats_chapitres.py puis lancer la mise à jour des informations statistiques.
Un tag ajouté aux entêtes de chapitre permet de définir des objectifs de mots. :target_500: définit une cible à 500 mots, :target_1200: défniit la cible à 1200. Cela permettra au générateur de statistiques d'affiner son avancée plus finement. Ce sont des indicateurs, dans la réalité les auteurs écrivent leurs chapitres avec des volumes très variables.
Suivi de progression de la rédaction
Il est envisagé que chaque génération de mise à jour des statistiques remplisse un fichier csv de suivi daté afin de pouvoir voir sa progression quotidienne. La génération de données statistiques peut être incluse dans une tâche cron pour ne pas avoir à faire de lancement de commande tous les jours.
Exemple de cronjob pour lancer le suivi toutes les heures, adaptez le chemin du script dans le dossier du livre concerné:
0 * * * * /usr/bin/python3 /home/user/book_generator/mon_livre_exemple/follow_progress.py
Ceci alimente un fichier csv de suivi des évolutions et présente les changements de mots du jour, ainsi que depuis la semaine dernière.
Le CSV contient les décomptes de mots pour livre.org, personnages.org, le nombre de personnages, de chapitres, et de sous chapitres.
Licence
AGPLv3+
Contacts:
contact+book_generator@cipherbliss.com @tykayn@mastodon.cipherbliss.com